Gen AI Can Deliver Trillions - Are You Ready to Capture it?
If you’re under pressure to start a Generative AI product strategy for your company, you are not alone. A recent survey of 400 senior AI professionals at organizations with annual revenue above $3 billion shows that more than 60% of them are likely to adopt Generative AI in the next 12 months, while 45% of the respondents have already started their Generative AI experiment.
At Pinecone, we’re seeing an explosion of interest from engineering leaders at large enterprises. They come to us with similar questions: We have an ambitious AI plan; where should we get started, and how can we get it right?
This enthusiasm and sense of urgency come from the significant business impact Generative AI could bring. Mckinsey estimates that Generative AI has the potential to contribute approximately $2.6 trillion to $4.4 trillion yearly across 63 different use cases. In the banking sector alone, its full implementation across use cases could generate an extra $200 billion to $340 billion annually.
We are developing a series guiding you to navigate this exciting but noisy space and help your company capture the full potential of AI. Today we’ll be focused on addressing hallucination in Gen AI applications.
Retrieval Augmented Generation(RAG) stands out as a widely-adopted approach to address Gen AI hallucination. In this article, we’ll explain what AI hallucination is, the main solutions for this problem, and why RAG is the preferred approach in terms of scalability, cost-efficacy, and performance.
Hallucination - A Major Challenge in Building Generative AI Applications
The excitement around Generative has propelled the wide adoption of Large Language Models (LLMs). While LLMs like Meta’s Llama2 have made building AI applications easier than ever, they also come with many issues. And one of the most discussed concerns is AI hallucination. Hallucination is when LLMs make up answers but make them sound factual. Let’s take a look at the example below.
Let’s say a user comes to your AI Chatbot and wants to figure out how to turn off the automatic reverse braking on the Volvo XC60. Your chatbot generates the answer below:
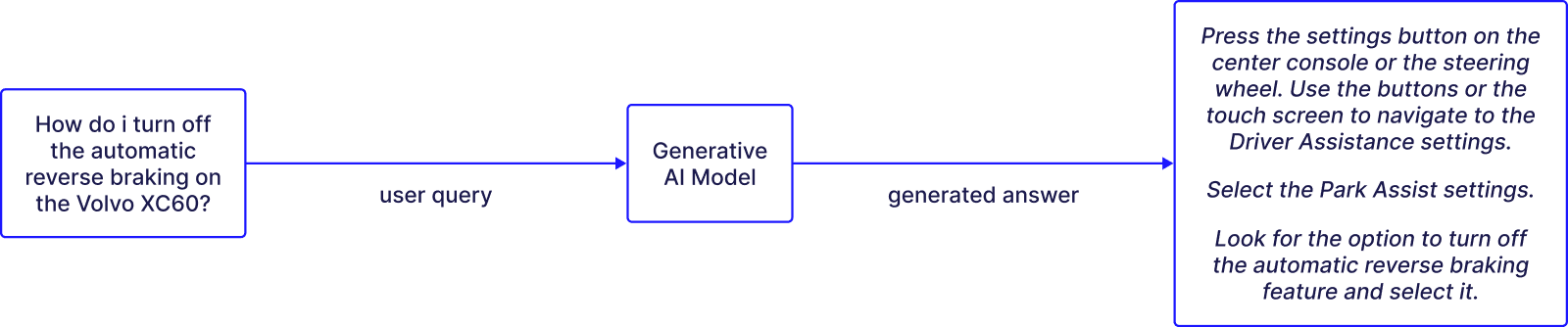
It may sound plausible with accurate grammar and seemingly reasonable steps, but it’s a total hallucination. What causes AI applications to hallucinate?
Reasons for AI Hallucination
There are two main reasons for hallucination:
LLMs are trained largely from information scraped from the Internet
They don’t have access to a much larger corpus of information that is proprietary and stored in corporate data warehouses. Because they are trained largely from information scraped from the Internet, which unfortunately also encodes all kinds of dangerous misinformation, they can produce wrong and even harmful outputs. Even though the teams behind those LLMs like Claude highlight their effort in red teaming, this remains a huge problem for most, if not all, LLMs today.
LLMs suffer from knowledge cutoff
Training LLMs is time-consuming and extremely expensive. OpenAI’s Sam Altman estimated it cost around $100 million to train the foundation model behind ChatGPT. But they become quickly out-of-date with respect to any recent information. This is called knowledge cutoff, meaning that LLMs are unaware of any post-training event.
For example, ChatGPT/GPT-4 is unable to provide answers after September 2021. If the answer you're looking for requires up-to-date information, proprietary company data, or even the current weather in New York, you're likely to get a hallucination without additional and timely context.
Hallucination is concerning because the LLMs generating them don't know they're hallucinating. They are designed to respond with convincing-sounding text output, so it requires a human expert to pay attention to notice hallucinations at the moment. If your model is talking directly to your customers and hallucinating, it can lead to lost customer trust and a damaged brand.
The factually wrong answers could be very dangerous in certain cases, like giving incorrect instructions about how to turn off a certain braking mode in your car.
Main Approaches to Reduce Hallucination
There are a few main approaches to building better AI products, including 1) training your own model, 2) fine tuning, 3) prompt engineering, and 4) Retrieval Augmented Generation. Let’s take a look at those options and see why RAG is the most popular option among companies. We’ll evaluate each option on their scalability (cost and complexity) and performance.
Train your own foundational model
Many large enterprises are investigating training their own foundation models on their own proprietary, domain-specific data.
To train a foundational model, you need to jump through several hoops, including acquiring a diverse dataset for training the foundation model on various tasks, preparing the dataset, configuring training parameters, algorithm architecture, computational resources, and more before you can deploy the model for user access.

This is the most complex, costly, and time-consuming approach of all. You’ll need 1) expertise - a top-notch team including machine learning experts and system engineers, 2) a significant amount of computing resources, and 3) massive labeled data sets. While it can improve accuracy with training in domain-specific data, it doesn’t solve the problem that a model won’t have access to recent or real-time data.
Fine Tuning
Fine-tuning is the process of providing additional training to a model with a smaller task-specific dataset.
For example, if you’d like to build a sentiment analysis product using fine tuning, you’ll need to choose a pre-trained LLM and fine tune it on an additional dataset with financial news and market reports etc.

Although it’s less resource-intensive than training your own model, it’s still complex and costly. You need to repeatedly invest significant time, money, and effort in labeling tasks, while also continuously overseeing quality changes, accuracy fluctuations, and shifts in data distribution. If your data evolves, even a fine-tuned model can’t guarantee accuracy. It doesn’t give your products long-term memory; you have to update your model constantly.
Prompt Engineering
Prompt engineering refers to experimenting with your instructions to the AI model so it can generate optimal results.
This is the easiest and least costly approach, as you can update your prompts easily with just a few lines of code, but it delivers the least improvement in terms of addressing hallucinations. LLMs accept not just prompts but also context, which is additional relevant information provided to the model for consideration when generating the answer. Prompt engineering doesn’t provide any meaningful new context.
Why RAG is the Preferred Approach to Deliver Enterprise-Grade Gen AI Products
Retrieval Augmented Generation refers to the process when your Gen AI application fetches specific and relevant context and provides it to the LLM at generation time. The image below shows how RAG solves hallucination in the Volvo case.
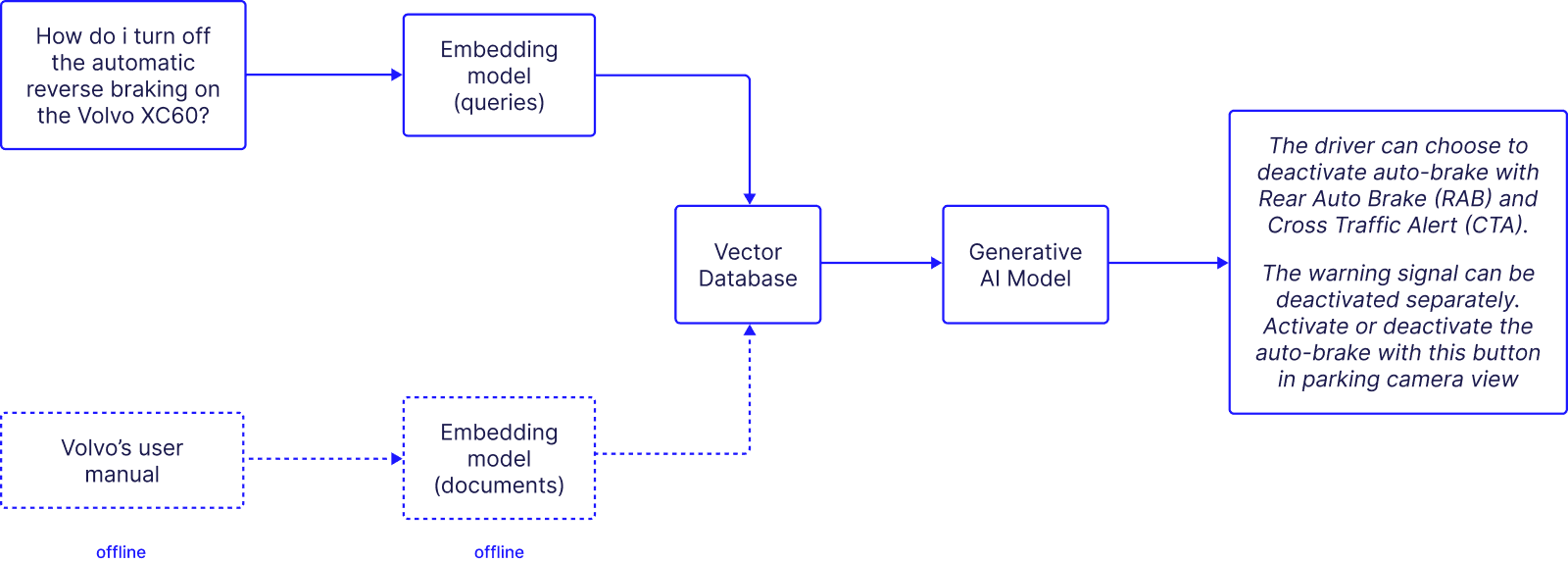
- Query: A user sends a query to the chatbot.
- Contextual search: This is the step where the query gets additional context with your Gen AI application searching and retrieving contextual information from external data sources.
- Inference: The LLM receives the original query sent by the user with the additional context. This significantly increases the model’s accuracy because it can access factual data.
- Response: The LLM sends the response back to the chatbot with factually correct information.
With the RAG model, our user can finally get the right answer to turn off the automatic reverse braking on the Volvo xc60.
Understanding Embeddings and Vector Database in RAG
The above flow shows the high-level framework of RAG. To fully understand its implementation details, you need to know semantic search. Semantic search, unlike keyword-based search, focuses on the meaning of the search query. It finds relevant results with similar meanings even if the exact words don’t match.
To do a semantic search, you need to convert the user’s query into embeddings, a type of numeric data representation that carries within it semantic information that’s critical for the AI to gain understanding and maintain a long-term memory they can draw upon when executing complex tasks. These embeddings are then sent to the vector database that stores the embeddings of your proprietary data. The database conducts a "nearest neighbor" search, identifying vectors that most closely match the user's intent. Once the vector database retrieves the nearest vectors, your application supplies them to the LLM through its context window, guiding it to execute its generative response.
Achieve Performance, Cost Efficiency, and Scalability with RAG
Semantic Search and RAG provide dramatically more relevant search results than a keyword search. As a result, most companies are moving to this approach when they build their GenAI applications. Together with LLMs, they are one of the two key technologies for building great generative AI applications today.
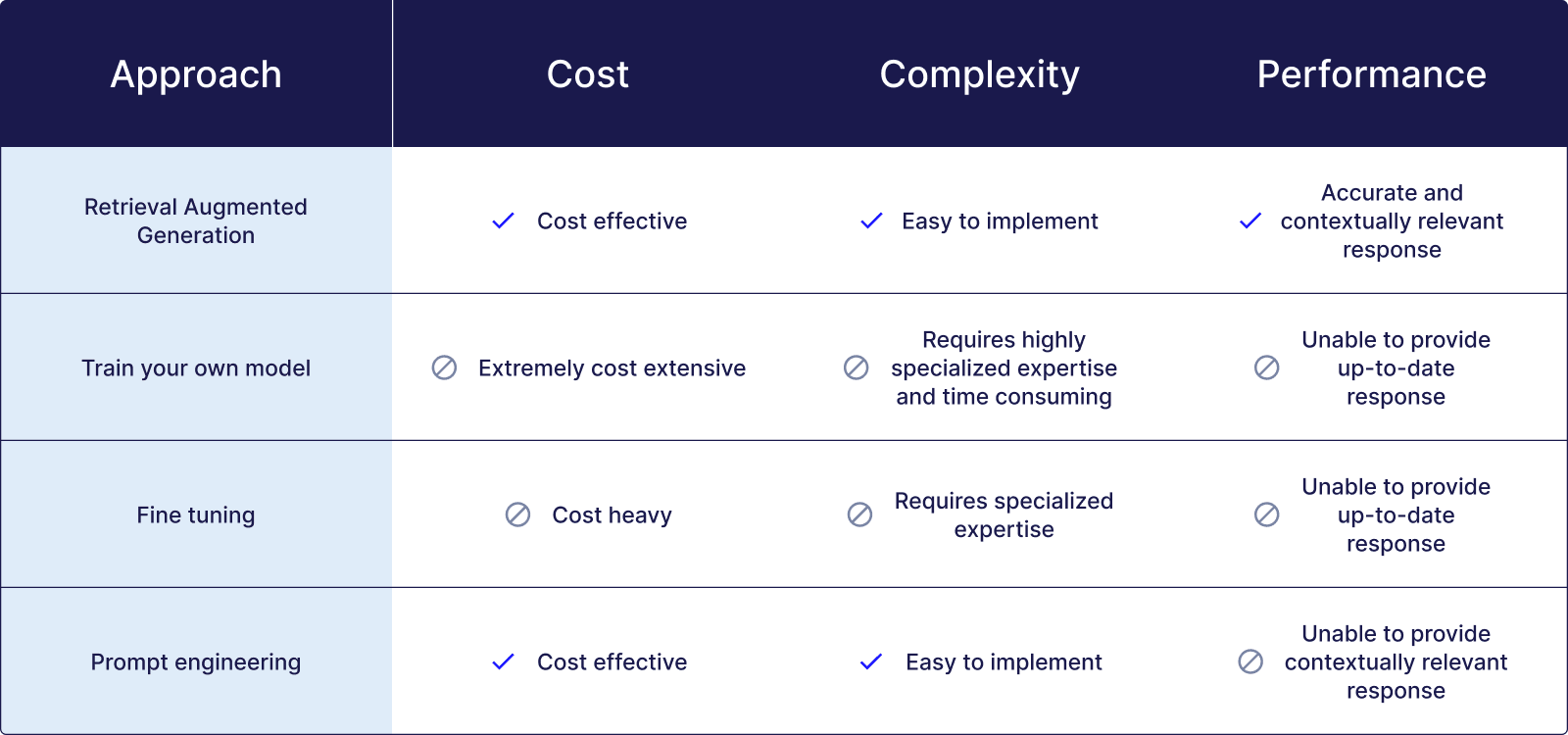
Compared to other approaches, RAG is much easier to implement because it doesn't require machine learning experts. Your application developers can figure it out relatively quickly and implement it in your GenAI apps. If you’re using Pinecone, you can get started in seconds.
RAG allows you to generate more contextually relevant responses with improved accuracy, especially for intricate queries demanding a profound knowledge of the subject. Additionally, RAG can be customized for particular sectors, making it a versatile instrument for a range of uses in finance, e-commerce, software development, and more. Unlike pre-trained models, RAG can leverage inherent knowledge that can be readily adjusted or even augmented on the go. This empowers researchers and engineers to manage recent knowledge without the need to retrain the entire model, saving time and computational resources.
What’s Next?
Understanding that RAG is the most cost-effective approach to improving your Generative AI performance is only the start. We’ll dive into more topics as you start your Generative AI journey. Stay tuned.
If you want to catch up in the Generative AI competition, don’t wait around. Contact our experts now and learn how Pinecone can help you deliver better results.