Today, we're excited to announce that our reranking model — pinecone-rerank-v0 — is now available in public preview.
Designed to significantly enhance enterprise search and retrieval augmented generation (RAG) systems, this new model provides a powerful boost in relevance and accuracy, ensuring that your search results and AI-generated content are grounded in the most relevant and contextually precise information.
Whether you're looking to improve internal search capabilities or strengthen your RAG pipelines, our new reranker is built to meet the demands of modern, large-scale applications while delivering top-tier performance.
Below, we’ll quickly cover:
- Why retrieval quality matters in the context of RAG systems
- How you can get started, quickly and easily, with pinecone-rerank-v0
- The results of putting pinecone-rerank-v0 to the test against alternative models
Why RAG matters
Large language models (LLMs) are powerful tools, but they have limitations that can affect response accuracy and relevance in real-world applications. RAG addresses this by providing the LLM with only the most relevant information, resulting in responses that are grounded in contextually precise, up-to-date data.
LLMs trained on broad datasets can’t directly access proprietary or domain-specific information, which often leads them to generate answers that may sound plausible but lack accuracy. RAG fills this gap by retrieving the right data when it’s needed, so the model’s responses are informed by specific, relevant information. At the same time, more context isn’t always better. Large input windows can lead to information overload, where key details get diluted. By retrieving only what’s essential, RAG keeps responses focused and reduces the “lost in the middle” effect that can impact output quality.
This targeted retrieval approach also reduces token costs—an important factor in production environments where tokens are a primary cost driver. By cutting token usage by 5-10x, RAG makes high-quality responses more scalable and cost-effective. Finally, retrieval accuracy is key for RAG to work as intended. Purpose-built neural retrieval models ensure that only the most relevant information reaches the model, enabling RAG to deliver responses that meet real-world demands for precision.
Note: Our in-depth article provides a closer look at how RAG overcomes LLM limitations and optimizes cost.
What is a reranker?
In retrieval systems, rerankers add an extra layer of precision to ensure that only the most relevant information reaches the model. After the initial retrieval — where an embedding model and vector database pull a broad set of potentially useful documents — rerankers refine this set by re-evaluating the results with a more sophisticated model. This step sharpens the relevance of the selected documents, so the generative model receives only high-quality, context-rich input.
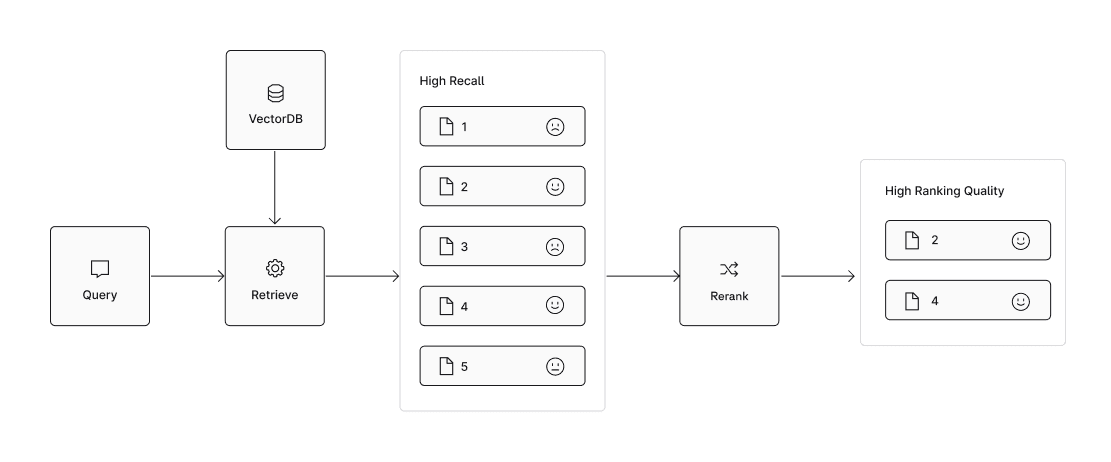
This precision is essential within RAG frameworks. Since the generative model’s output relies on the quality of its input, rerankers help ensure responses are both accurate and grounded. By combining the broad reach of neural retrieval with the targeted precision of rerankers, RAG systems can deliver more reliable and relevant answers — especially important in applications where precision matters most.
Introducing Pinecone's reranker
Our latest model, pinecone-rerank-v0, is optimized for precision in reranking tasks using a cross-encoder architecture. Unlike embedding models, the cross-encoder processes the query and document together, allowing it to capture fine-grained relevance more effectively.
The model assigns a relevance score from 0 to 1 for each query-document pair, with higher scores indicating a stronger match. To maintain accuracy, we’ve set the model’s maximum context length to 512 tokens—an optimal limit for preserving ranking quality in reranking tasks.
Putting the reranker to the test
To quantify — as objectively as possible — the improved effectiveness of our new reranker model, we performed an evaluation on several datasets:
- The BEIR benchmark is a widely used evaluation suite designed to assess retrieval models across various domains and tasks. It includes 18 different datasets covering a range of real-world information retrieval scenarios, allowing models to be tested on diverse challenges like biomedical search, fact-checking, and question-answering.
- TREC Deep Learning is an annual competition hosted by the National Institute of Standards and Technology (NIST), focused on web search queries across a diverse web corpus.
- Novel datasets Financebench-RAG and Pinecone-RAG (proprietary) that reflect real-world RAG interactions.
For both TREC Deep Learning and BEIR, we retrieved and reranked 200 documents and finally measured Normalized Discounted Cumulative Gain (specifically, NDCG@10). For Pinecone-RAG and Financebench-RAG, we retrieved and reranked up to 100 documents (some collections were smaller than this) and finally measured Mean Reciprocal Rank (specifically, MRR@10).
MRR@10 and NDCG@10 were calculated with the respective metrics (MRR and NDCG) considering only the top 10 ranked candidates.
We compared with an extremely large set of reranking models, but here we present a selection of those that we consider more competitive:
- Cohere’s latest models are cohere-v3-english and cohere-v3-multilingual, for English and Multilingual reranking respectfully.
- Voyage AI’s generalist reranker optimized for quality with multilingual support, voyageai-rerank-2.
- The model offered by Jina AI built for Agentic RAG, jina-v2-base-multilingual.
- The high-performance, multilingual model by Beijing Academy of Artificial Intelligence (BAAI), bge-reranker-v2-m3.
- The latest reranking model, google-semantic-ranker-512-003, from Google’s RAG experience in Vertex AI Agent Builder.
The models for Cohere, Voyage AI, and Google were tested using the official APIs, while the models from Jina AI and BAAI were hosted locally since they are publicly available.
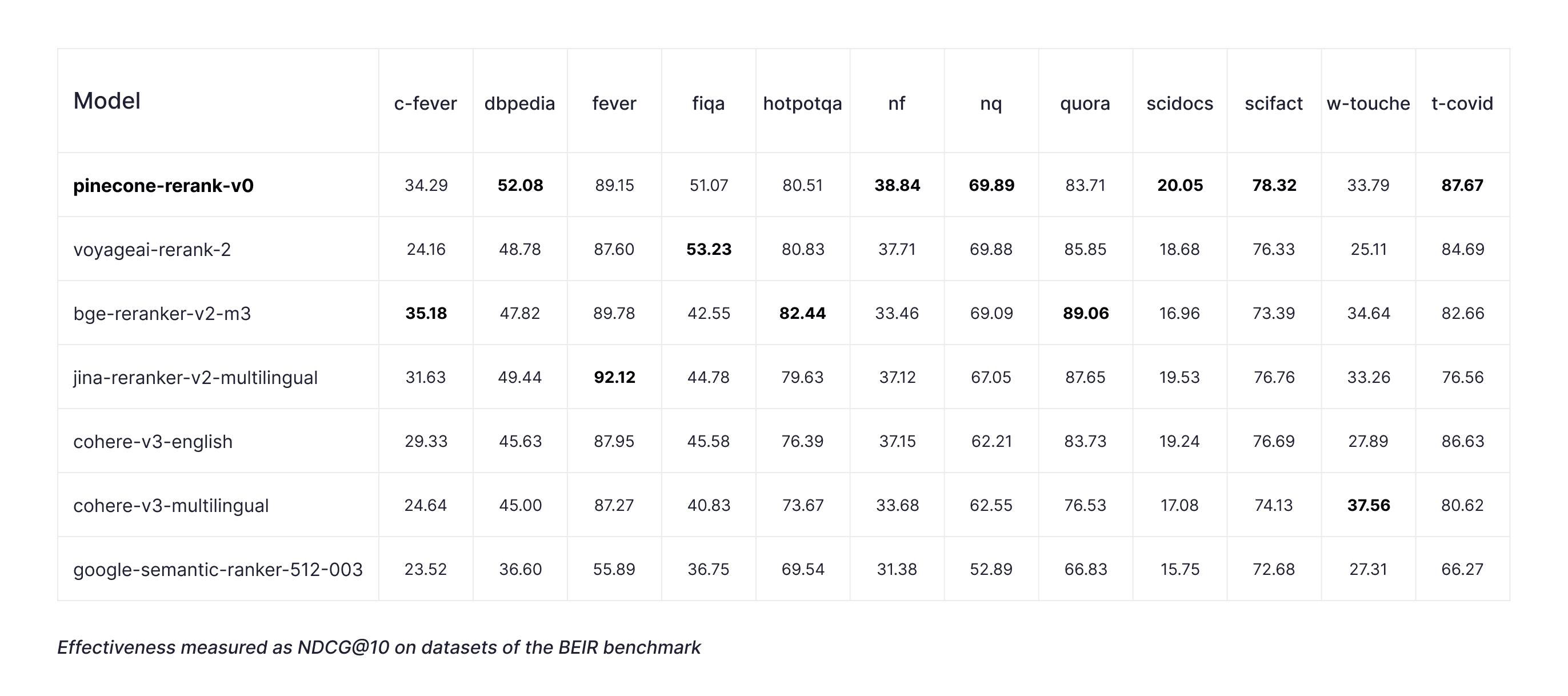
BEIR
For the BEIR benchmark, we focused on 12 datasets, excluding the four that are not publicly available to ensure reproducibility. We also excluded MS MARCO, as it is evaluated separately, and ArguAna, since its task of finding counter-arguments to the query contrasts with the purpose of a reranker.
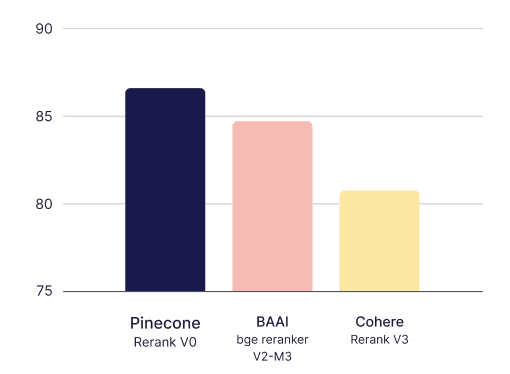
- Pinecone-rerank-v0 had the highest average NDCG@10, notably higher than the alternatives
- Pinecone-rerank-v0 performed the best on 6 out of the 12 datasets; the second-best reranking model performed the best on only 3
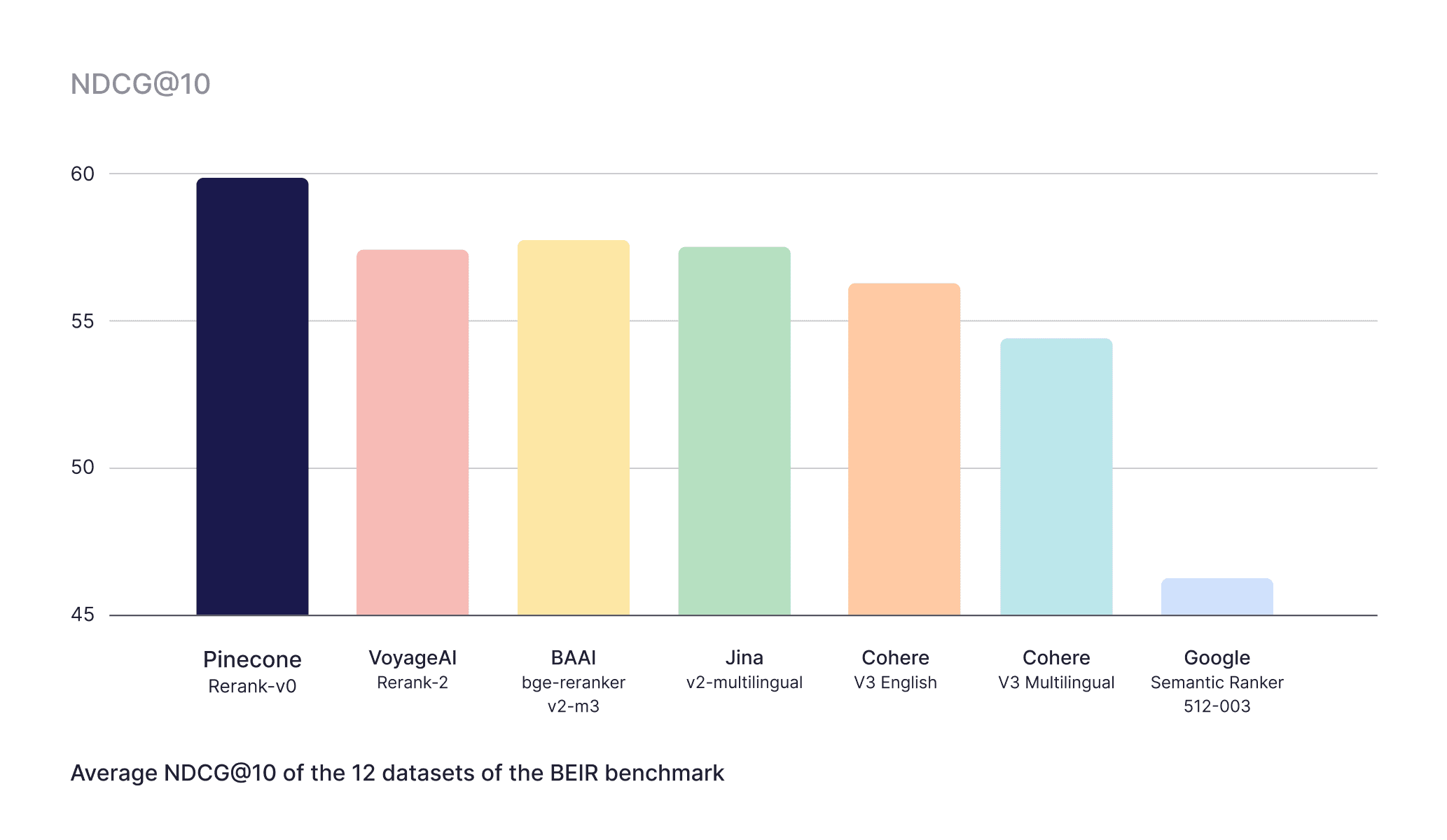
Pinecone-rerank-v0 demonstrates significant improvements in search accuracy (NDCG@10) in various scenarios, achieving up to a 60% boost on the Fever dataset compared to Google Semantic Ranker, over 40% on the Climate-Fever dataset relative to cohere-v3-multilingual or voyageai-rerank-2, and 20% on FiQA compared to bge-reranker-v2-m3. On average, Pinecone-rerank-v0 outperforms industry-leading models by 9% for NDCG@10.
TREC
For our TREC evaluation, we merged the datasets from the 2019 and 2020 editions, resulting in a total of 97 queries tested against a collection of 8.8 million documents. Once again, pinecone-rerank-v0 outperformed the other reranking models.
| Model | NDCG@10 |
|---|---|
| pinecone-rerank-v0 | 76.51 |
| voyageai-rerank-2 | 76.33 |
| bge-reranker-v2-m3 | 75.51 |
| jina-reranker-v2-multilingual | 75.72 |
| cohere-v3-english | 72.22 |
| cohere-v3-multilingual | 74.93 |
| google-semantic-ranker-512-003 | 64.89 |
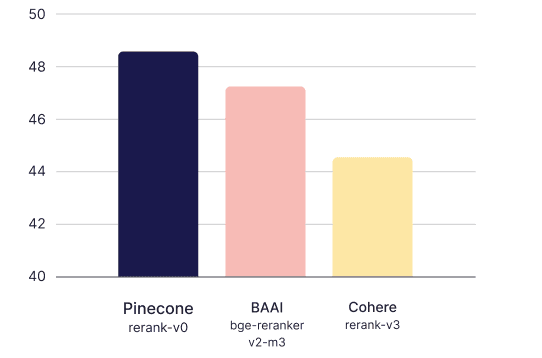
Financebench-RAG
The Financebench-RAG dataset is generated from the open-source financebench question-answering dataset. Text is extracted from the raw PDFs with pypdf, and then split into chunks of up to 400 tokens prior to embedding.
The initial retrieval stage is done using openai-large-3 embeddings scored with dot product. The top 100 candidates from the first retrieval stage are then reranked, and chunks are expanded out to the entire page. If multiple chunks from the same page are retrieved, the page’s score is taken to be the average of the chunks on it. These pages are then ranked based on score.
Pinecone-RAG
The Pinecone-RAG dataset reflects real-world RAG interactions and is annotated by Pinecone. This data is not publicly available and was not used in training, thus showcasing the model's 0-shot performance.
After reranking the final candidates with the corresponding reranker, we calculate the standard MRR@10 metric (described above) based on the final rank of the top 10 final candidate documents after reranking.
Getting started
Pinecone-rerank-v0 is accessible through Pinecone inference and is now available to all users in public preview.
Note that this endpoint is intended for development. For improved performance, contact us directly for an optimized production deployment.
from pinecone import Pinecone
pc = Pinecone("PINECONE-API-KEY")
query = "Tell me about Apple's products"
documents = [
"Apple is a popular fruit known for its sweetness and crisp texture.",
"Apple is known for its innovative products like the iPhone.",
"Many people enjoy eating apples as a healthy snack.",
"Apple Inc. has revolutionized the tech industry with its sleek designs and user-friendly interfaces.",
"An apple a day keeps the doctor away, as the saying goes."
]
results = pc.inference.rerank(
model="pinecone-rerank-v0",
query=query,
documents=documents,
top_n=3,
return_documents=True
)
for r in results.data:
print(r.score, r.document.text)